S3 Static Hosting Issues
Introduction
NuxtContent allows me to generate a content centered blog post or article by writing in Markdown. I can author with simple text editor without fussing with HTML codes, css, etc. It even handles things like custom SEO and Social Sharing metadata with front-matter variables at the top of the Markdown file. The Markdown document encapsulates all the key programmer principles of simplicity, flexibility, readability, and self-containment. Indeed this blog post was written this way. Further, with the use the Nuxt npm run generate command I can turn my fully client functional Vue.js/Nuxt.js web application into a static website that I can deploy to a cheap storage hosting solution such as Amazon AWS S3 Static website hosting.
Static Files Layout
When I author a page article and then generate a static site with NuxtContent (i.e. npm run generate), it converts each Markdown document and the supporting Nuxt/Vue framework files into an html file, a payload file, and a directory. There are two static page layout options:
- Index Static Output (default)
- Flat Static Output
The output layout choice is controlled by the autoSubfolderIndex key in nuxt.config.ts file.
{
nitro: {
prerender: {
autoSubfolderIndex: true,
}
}
}
Index Static Output
When autoSubfolderIndex: true (and it is true by default), a subdirectory is created for each markdown file and the directory has two files in it. For example if my markdown file was example.md, the following static files are generated.
example/
example/index.html
example/_payload.json
Flat Static Output
However, when autoSubfolderIndex: false, instead of an index.html inside the directory of the page name, it creates an .html file above the folder. For the example.md example, the output looks like this:
example.html
example/
example/_payload.json
S3 Static Host Issues
The AWS S3 bucket service can host static websites directly, even though recently a new capability to use AWS Amplify Hosting as a host service (for a minimal fee) is recommended. In trying to keep the hosting costs to minimum we use the AWS S3 service. In making that choice, the following issues are relevant for using AWS S3 for Nuxt static site website hosting:
- S3 Object Storage
- S3 Web Server Behavior
- Trailing Slash
S3 Object Storage vs File System
AWS S3 Service is actually an object store and not a file system. The differences between the two are normally negligible but are important for static web hosting. Specifically each file and directory gets created as an object with a key name.
For the two different static site formatting options, the following bucket objects are created:
Index Layout Objects
example/index.html
example/_payload.json
example/
Flat Layout Objects
example.html
example/_payload.json
example/
S3 Web Server Behavior
The S3 Web Server behavior is 'quirky' when it comes to pages and pages in directories. Further, it has a different mechanism for the root-level URL 'home' differently than other pages.
Home
For the root-level URL, i.e. home, the trailing slash is optional. AWS S3 Static website hosting has a built in property specifying the html file to deliver, usually index.html at the root. This is setup as a property of of the S3 static website hosting for the 'Index document'. The result of this, for when the user uses the root with or without the trailing slash, i.e. http://<root url> or http://<root url>/ the S3 Web server will deliver the index.html file specified.
Pages
However, for all other non root-level URLs there is a different algorithm for determining the index.html for that URL. The behavior is as described in their AWS S3 website hosting documentation 'Configuring an index document'.
Summarizing that behavior:
- If a page URL request has a page name with a trailing slash, '/', the AWS S3 Web Server will return
/<pagename>/index.htmlobject if it exists or 404 if it doesn't.- For example, a request to
http://example.com/photos/will return a 200 OK with the AWS S3 bucket objects3://example.com/photos/index.html.
- For example, a request to
- If a URL request has a page name without a tailing slash, '/', the AWS S3 Web Server first looks for a page name object in the bucket, then an index.html file in the page name folder with a 302 return, or finally a 404 if it doesn't find either one.
- For example, a request
http://example.com/photoswill return- 200 OK with the AWS S3 bucket object of
s3://example.com/photos - 302 Temporarily moved with the AWS S3 bucket object of
s3://example.com/photos/index.html - 404 Not Found
- 200 OK with the AWS S3 bucket object of
- For example, a request
Pseudo Code
The behavior using pseudo-code for the network transactions
- If called WITH a TRAILING SLASH, i.e.
http://<root url>/<page name>/- if
s3://<root url>/<page name>/index.htmlexists- 200 OK
- else
- 404 Not Found
- if
- If called WITHOUT TRAILING SLASH, i.e.
http://<root url>/<page name>- if
s3://<root url bucket name>/<page name>exists- 200 OK
- else if
s3://<root url bucket name>/<page name>/index.htmlexists- 302 Temporarily Moved to
http://<root url>/<page name>/
- 302 Temporarily Moved to
- else
- 404 Not Found
- if
302 vs. 301
Why AWS S3 Static Web Server uses a a 302 error instead of a 301 Permanently Moved error in not clear. A 301 would help web crawlers like Google or Bing to register that photos should be photos/ for example.
One can implement a solution to change 302 to 301 by using a Lambda function for CloudFront Edge requests. See this blog for details.
Index Static Output - Issues
While an AWS S3 site will generally work when you employ the Nuxt Index Static Output (default, autoSubfolderIndex: true) and host it on Amazon AWS S3, there are significant drawbacks.
- While your browser bar doesn't have a trailing slash, all your SEO pages will have a trailing slash and looks obsolete
- All your page URL requests without a trailing slash (how people normally type it) will load slower, due 302 re-directions.
- In testing, a URL request to a page without a trailing slash required 77 network calls whereas if with a trailing slash was included, only 56 network calls.
- Social 'share' buttons and users copying the website URLs directly from the browser bar will embed social media links that a social platform crawler will not preview, because it does not get a 200 OK response from it (it gets a 302).
- For example, X/Twitter tweet/post/DM will not provide site preview in the composer.
- Sitemap generation, internal NuxtLink and
<a href=''></a>elements won't contain the ending slash either which will confuse crawlers with constant 302 redirects as it crawls.
Index Static Output - X Validator Issues
An example of the issues on posting links to a social media site, can be seen at the X/Twitter card validator tool
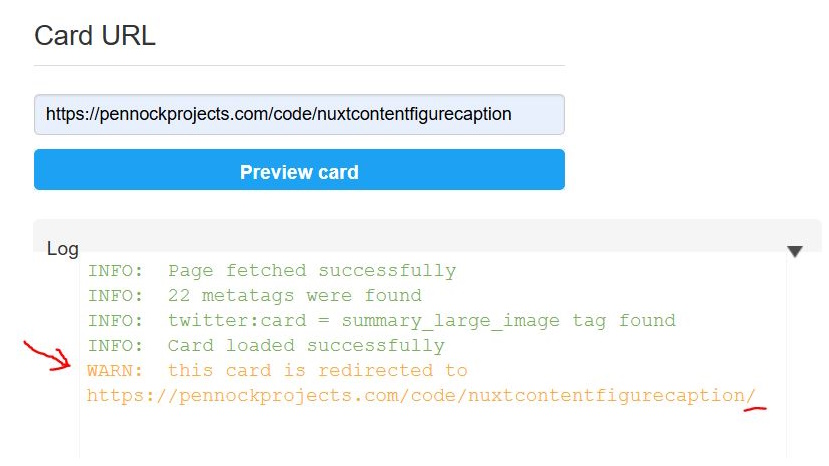
A static site URL without a trailing slash generates warnings
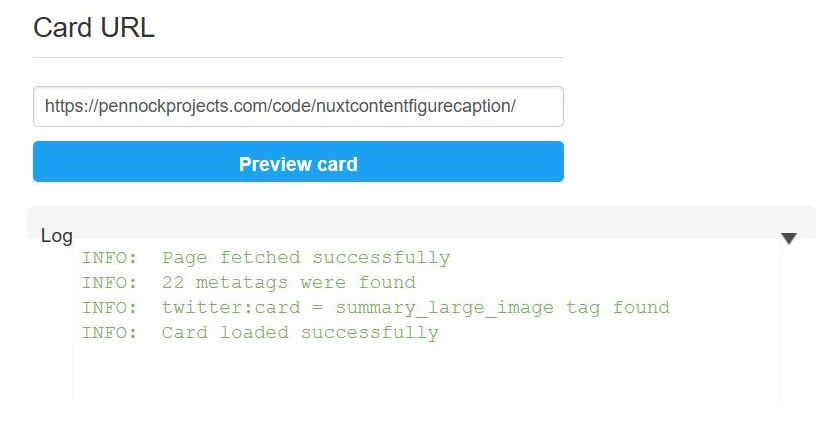
A static site URL + trailing slash gives no warning
Index Static Output - Conclusion
The lack of easy social share and user url posting is a non-starter for content heavy sites like a blog or articles site.
Flat Static Output - Issues
With the other layout option, the Nuxt Flat Static Output (autoSubfolderIndex: false) it has even more significant drawbacks:
- When you request a page without the
.htmlextension, with or without a trailing slash, it returns a 404 Not Found result. i.e.https://pennockprojects.com/projectsorhttps://pennockprojects.com/projects/both return a 404 Not Found. - When you request a page with the
.htmlextension, it returns a 200 OK result. i.e.https://pennockprojects.com/projects.htmlreturns a 200 OK and the Nuxt web site is fully functional from there.. - If you do load the app successfully, either from the home page or a page with the
.htmlextension, then navigating to other pages the url for the app does not have the.htmlextension. Therefore if the user refresh at the page, or if a user copies those links, they will get a 404 Not Found.
A Workaround
Not wanting to move to AWS Amplify for better static site handling, I wrestled with this issue for my own blog site and for the JAMStart project when I discovered a workaround.
AWS S3 Object Storage
In reading about how the AWS S3 website hosting index documents and folders work, the first item of what happens for a non-trailing slash page jumped out to me.
if you exclude the trailing slash from the preceding URL, Amazon S3 first looks for an object (emphasis mine)
photosin the bucket
What if I used the Flat Static Output but then renamed the projects.html to projects in the AWS S3 bucket? This is only possible because the AWS S3 bucket system you can have objects named projects and projects/.
An Experiment
So, I manually, using the AWS S3 web tool, renamed the projects.html object to projects.
projects
projects/
projects/_payload.json
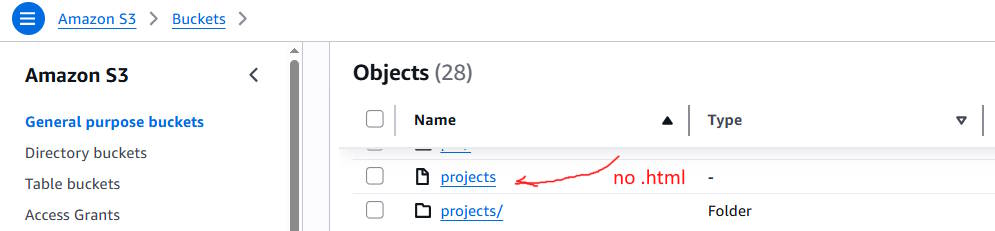
Amazon S3 Bucket Objects with Page Name and Page Name Folder
Solution
This workaround resolved most my issues.
- Requests to
/projects(without trailing slash) returned the proper html because the objectprojectsexisted. - The HTTP Get produced a 200
- The Nuxt web app loaded up properly and all the internal navigation worked properly from there.
- SEO pages were clean
- Social posting worked
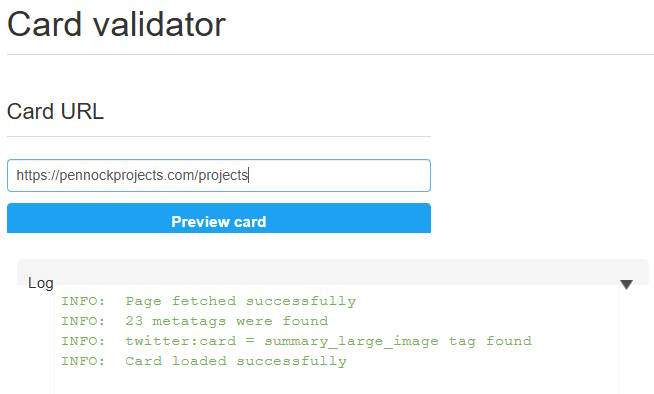
A static site URL without a trailing slash 200 clean
Workaround Issue
The one remaining issue was that requests to /projects/ (with trailing slash) returned a 404 Not Found because the object projects/ existed but there was no index.html object in it. However, this is a minor issue as most users will not type in the trailing slash and if they do, they can easily correct it.
Operational Future Fix
In order to use this workaround, there are a couple of of items to address.
- An automatic way to scan for all pages. Manually doing this is error-prone and laborious.
- The fix needs to be applied to the S3 bucket itself and can't be fixed at build time or with layout. This is because the build machine uses a file system to layout the files and unlike an S3 bucket objects which distinguishes between a directory and a file, a file system does not. i.e. it can't have a file named
projectsand a directory namedprojects/at the same time. - The fix needs to be part of a CICD pipeline so that it is hands-free and repeatable.
See Nuxt Static S3 Fixes for how to approach turning this workaround into an automated CICD solution.